
















 con una vibrante pantalla OLED de 7 pulgadas, que se lanzará el 8 de octubre")











 2023")


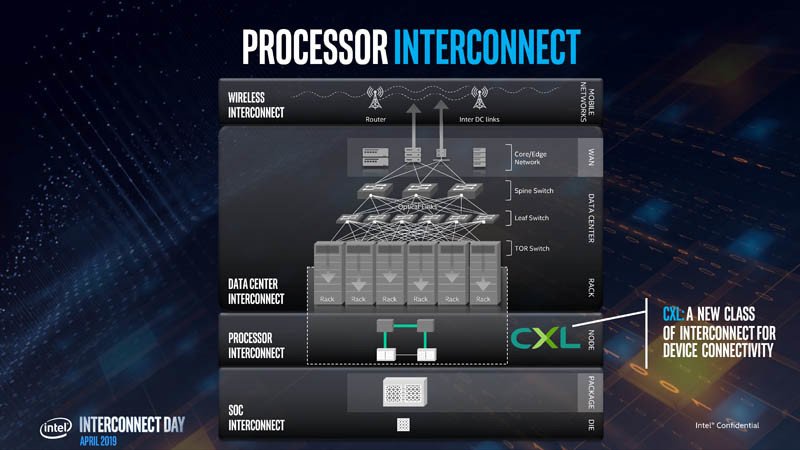
CXL, abreviatura de Compute Express Link, es una nueva y ambiciosa tecnología de interconexión para dispositivos de alto ancho de banda extraíbles, como los aceleradores de cómputo basados en GPU, en un entorno de centro de datos. Está diseñado para superar muchas de las limitaciones técnicas de PCI-Express, la menor de las cuales es el ancho de banda. Intel percibió que su próxima familia de aceleradores de cómputo escalables bajo la banda Xe necesita una interconexión especializada, que Intel quiere impulsar como el próximo estándar de la industria. El desarrollo de CXL también se desencadena por los mayores aceleradores de cómputo NVIDIA y AMD que ya tienen interconexiones similares propias, NVLink e InfinityFabric, respectivamente. En un evento dedicado denominado “Día de la interconexión 2019”, Intel presentó una presentación técnica en la que se explicaban las tuercas y tornillos del CXL.
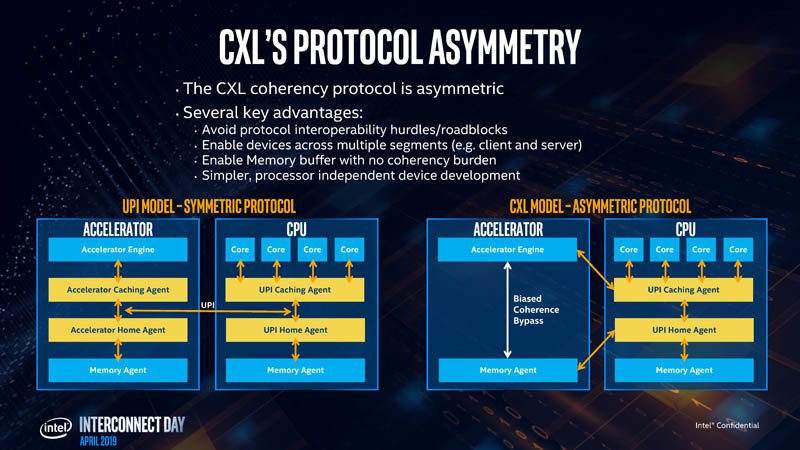
Intel comenzó describiendo por qué la industria necesita CXL y por qué PCI-Express (PCIe) no se adapta a su caso de uso. Para un dispositivo de segmento de cliente, PCIe es perfecto, ya que las máquinas de segmento de cliente no tienen demasiados dispositivos, memoria demasiado grande y las aplicaciones no tienen una huella de memoria muy grande o escala en múltiples máquinas. PCIe falla a lo grande en el centro de datos, cuando se trata de múltiples dispositivos hambrientos de ancho de banda y vastas agrupaciones de memoria compartida. Su mayor defecto son los grupos de memoria aislados para cada dispositivo y los mecanismos de acceso ineficientes. El intercambio de recursos es casi imposible. Compartir operandos y datos entre múltiples dispositivos, como dos aceleradores de GPU que trabajan en un problema, es muy ineficiente. Y por último, hay latencia, mucha. La latencia es el mayor enemigo de los grupos de memoria compartida que se extienden a través de múltiples máquinas físicas. CXL está diseñado para superar muchos de estos problemas sin descartar la mejor parte acerca de PCIe: la simplicidad y adaptabilidad de su capa física.


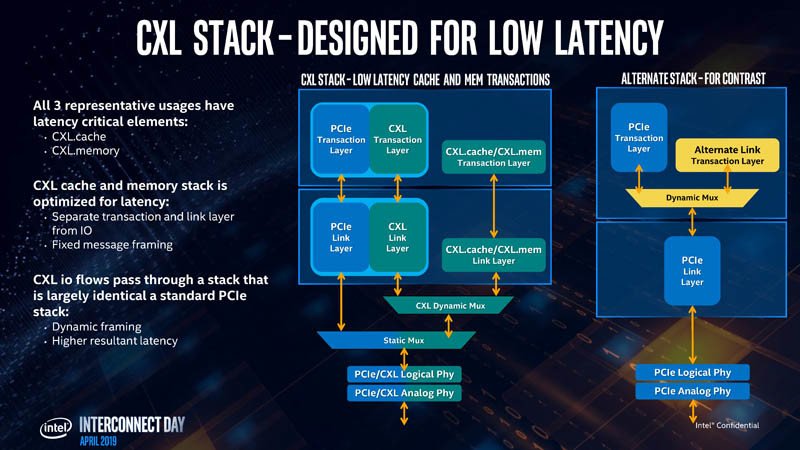
CXL utiliza la capa física PCIe y tiene un ancho de banda sin formato en el papel de 32 Gbps por línea, por dirección, que se alinea con el estándar PCIe gen 5.0. La capa de enlace es donde está toda la salsa secreta. Intel trabajó en un nuevo protocolo de intercambio, negociación automática y protocolos de transacción que reemplazan a los de PCIe, diseñados para superar las deficiencias enumeradas anteriormente. Con PCIe gen 5.0 ya estandarizado por PCI-SIG, Intel podría compartir la IP de CXL con SIG en PCIe gen 6.0. En otras palabras, Intel admite que CXL no puede sobrevivir a PCIe, y hasta que PCI-SIG pueda estandarizar la generación 6.0 (alrededor de 2021-22, si no más tarde), CXL es la necesidad de la hora.
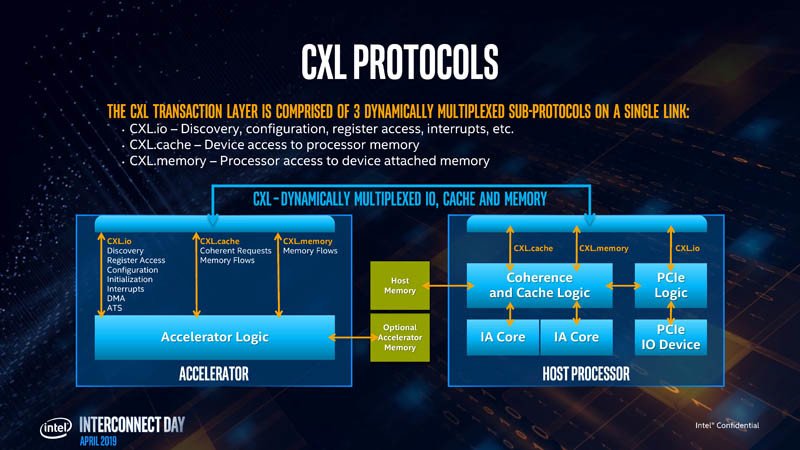
La capa de transacción CXL consta de tres subprogramas multiplexados que se ejecutan simultáneamente en un solo enlace. Estos son: CXL.io, CXL.cache y CXL.memory. CXL.io se ocupa del descubrimiento de dispositivos, la negociación de enlaces, las interrupciones, el acceso al registro, etc., que son básicamente tareas que hacen que una máquina funcione con un dispositivo. CXL.cache se ocupa del acceso del dispositivo a la memoria de un procesador local. CXL.memory trata el acceso del procesador a la memoria no local (memoria controlada por otro procesador u otra máquina).
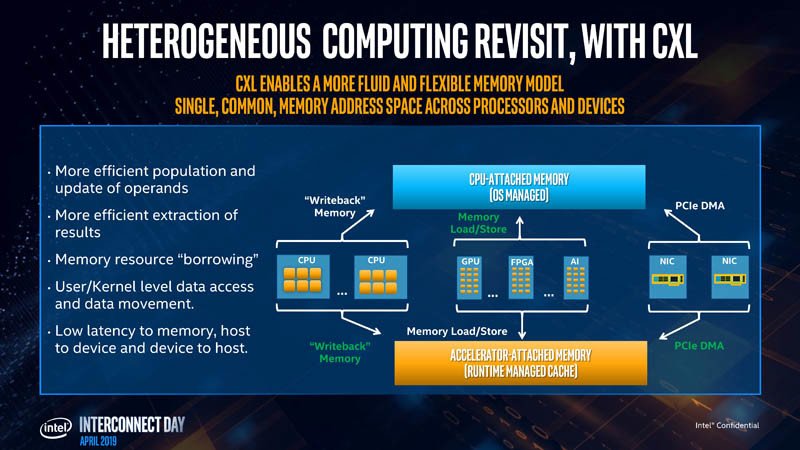

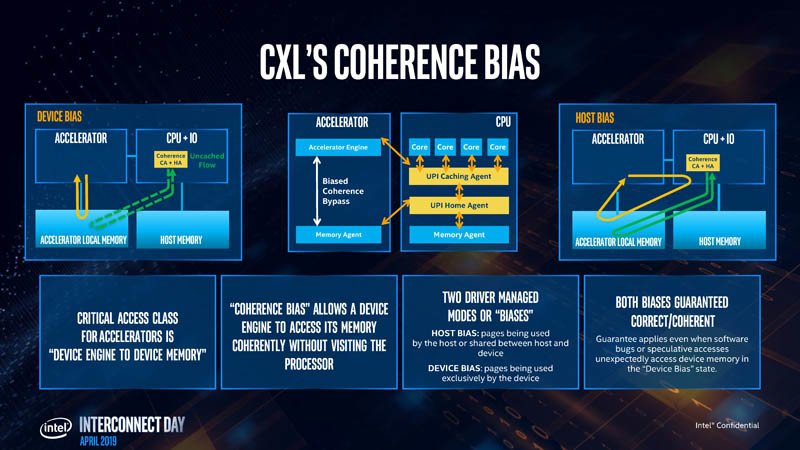
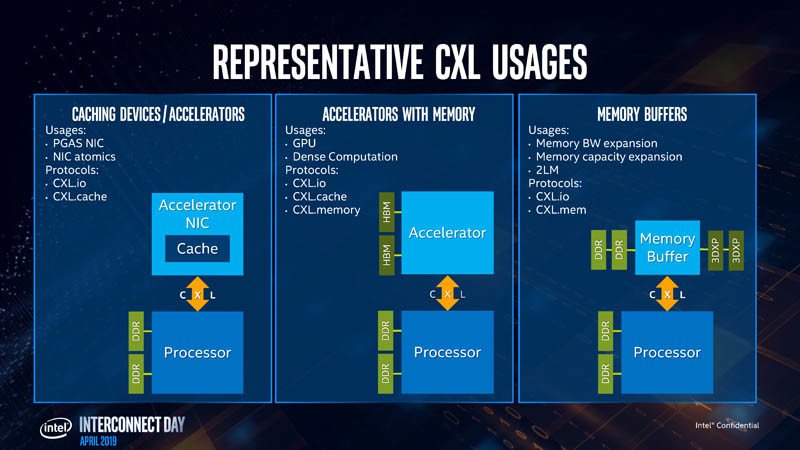
Intel enumeró los casos de uso para CXL, que comienza con aceleradores con memoria, como tarjetas gráficas, aceleradores de cómputo de GPU y tarjetas de cómputo de alta densidad. Los tres protocolos de la capa de transacción CXL son relevantes para dichos dispositivos. A continuación, son FPGAs, y NICs. CXL.io y CXL.cache son relevantes aquí, ya que los procesadores locales de la NIC procesan las pilas de red. Por último, están los buffers de memoria de suma importancia. Puedes imaginar estos dispositivos como “NAS, pero con DRAM sticks”. Los futuros centros de datos constarán de vastas agrupaciones de memoria compartidas entre miles de máquinas físicas y aceleradores. CXL.memory y CXL.cache son relevantes. Gran parte de lo que hace que la capa de enlace CXL sea más rápida que la PCIe es su pila optimizada (carga de procesamiento para la CPU). La pila CXL está construida desde cero manteniendo la baja latencia como objetivo de diseño.






{kind=link}